データの集合の中から、知識を発見しよう、というもの。
ルールの発見を目的とした活動とも表現できる
ここでいう知識とは、データの中に見られるルールとか法則。
最近データマイニングの紹介でよく使われるもの
ビールと紙おむつ
これは、スーパーで客の買った物を分析したら、紙おむつを買う人はビールを買うことが多い、という傾向が出てきた、ということです。
この、「紙おむつを買う人はビールを買うことが多い」というのがある種の知識なのです。このような知識をデータの中から機械的に、自動的に見つけよう、というのがデータマイニングです。
この、ビールと紙おむつのような関係でしたら、単純にお客さんの買い物リストのデータを見るだけで、発見できます。
しかし、例えば、5000円以上の買い物をしてくれる人は、ビールと紙おむつを買うか、トイレットペーパーとティシュペーパーと洗剤を買う(あくまで適当に考えた例ですが)、というような、複雑な形をした知識を見つけ出そうと思ったら、単純にデータを見るだけでは、とんでもなく時間がかかります。例えば、1000品目の中から5品目を組合せて5000円以上の買い物をする客がその組合せの買い物をしているかどうかをチェックするとしますと、およそ1000の5乗、1000兆回もデータを見なければいけません。たいていのコンピューターでは1日や2日で終わる計算ではありません。こういった知識の発見をするためには、数理計画やアルゴリズムの技術を使って、効率的な方法を考えないといけないのです。
もう1つ例を見てみましょう。車を買った人のデータを分析して、車を買う人の年齢と、買った車の金額についてどんな関係があるか調べるとしましょう。絵で書くと図のようになります。
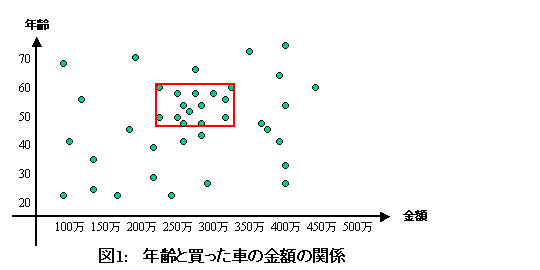
普通に考えて、年をとるほど高い車を買いそうだな、というのはあるんですが、例えば、図の赤線で囲った部分が示すように、48歳から60歳の人が230万から320万の車を買う可能性が高い、というような具体的な年齢層と購買価格帯がわかれば、効果的な宣伝ができるわけです。年齢を1歳刻みで20から70まで、車の価格を10万刻みで100万から500万まで調べるとすると、50×50×40×40の組合せを全てについてデータを検索する必要があるのですが、これは、アルゴリズムを工夫すると、50×40の組合せを調べるだけですむようになります。
昔から、こういったデータの分析には統計的な方法がとられていました。主成分分析や回帰分析などです。
データマイニングの練習用アドイン(エクセル)は
http://www.ohmsha.co.jp/data/link/4-274-06625-8/
テキストマイニングの練習用ソフトは
http://www.ohmsha.co.jp/data/link/4-274-06493-X/index.htm
http://www3.justsystem.co.jp/download/miningassistant/movie/index.html
商用データマイニングをするためのツール
