例
消費者金融会社が、お金を借りた人の年齢と年収と自己破産の関係を調べたいとします。集まったデータが図のようになっているとしましょう。
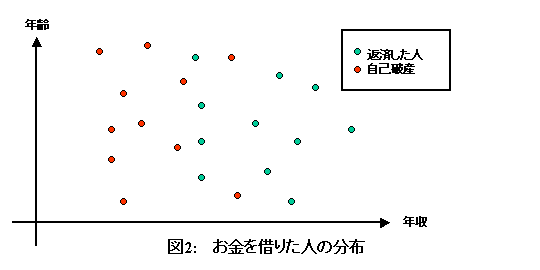
これはお金を借りた人それぞれを、年齢と年収に対応する位置に、破産した人なら赤で、そうでなければ緑で書いたものです。これを、赤の点、緑の点それぞれ、正規分布に従って分布しているのだ、と思って分布を推定すると、例えばこのようになります。
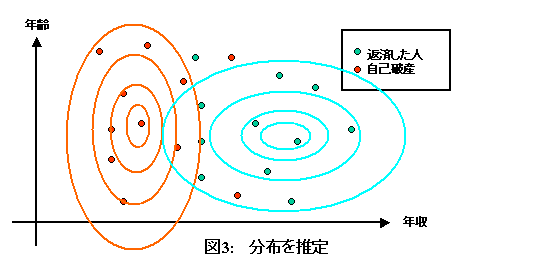
このように分布が推定できると、新しくお金を借りに来た人の年齢と年収がわかると、自己破産の確率はどれくらいかな、と推定できるわけです。データが多くなれば、それだけ推定も正確になります。ただ、「こういうふうに分布しているだろう」という分布の形の仮定が間違っていると、推定は全然当たらなくなります。この、分布の推定、というのがやっかいでした。
対して、最近開発された、データマイニングで研究されている方法の1つ、サポートベクターマシンという方法は、ちょっと発想が違います。赤い点のグループと緑の点のグループを、直線を使って分割してしまおうというものです。この図のように。
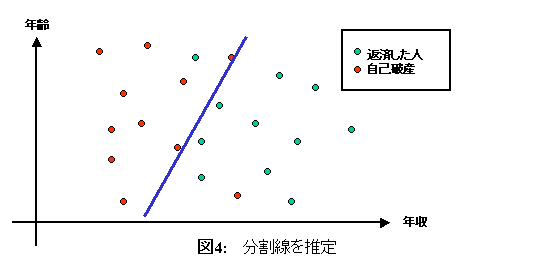
このとき、直線の片方側にはなるべく赤い点が多くなるように、もう片方の側には緑の点が多くなるように、直線を決めよう、というものです。なるべく上手にグループ分けをする、最適化問題を解くわけです。新しいお客さんが来たときに、その年齢と年収を聞いて、この線のどっち側にお客さんが来るか、で自己破産しそうな人かどうかを判定しよう、というものです。この方法だと、データがどういう形の分布になっているか、さっぱりわからなくても、データから直接、こういった直線を得られる、というのが強みです。データの分布がわからないから上手に分析・予測ができなかった問題に対して、解決法を提示できる可能性があるわけです。
